Data Analysis Methods Techniques and Process Types vs Analytics
Data analysis is the practice of examining raw information to find patterns, draw conclusions, and support decisions. It sounds straightforward, but in practice the term covers a wide range of methods, each suited to different questions and datasets. Descriptive statistics and regression modeling are both data analysis, but they answer different things. The process — from raw data to insight — follows recognizable steps, though the specific techniques vary by domain. Platforms like Casino Bossy apply data analysis techniques to track player behavior, evaluate game performance, and identify trends in real-time operational data, much like analysts in any data-rich environment.
Understanding the landscape of analysis methods saves time when starting a new project. Choose the wrong technique for your data type and you get misleading results. Choose the right one and even a modest dataset can answer meaningful questions.
Types of Data Analysis and When to Use Each
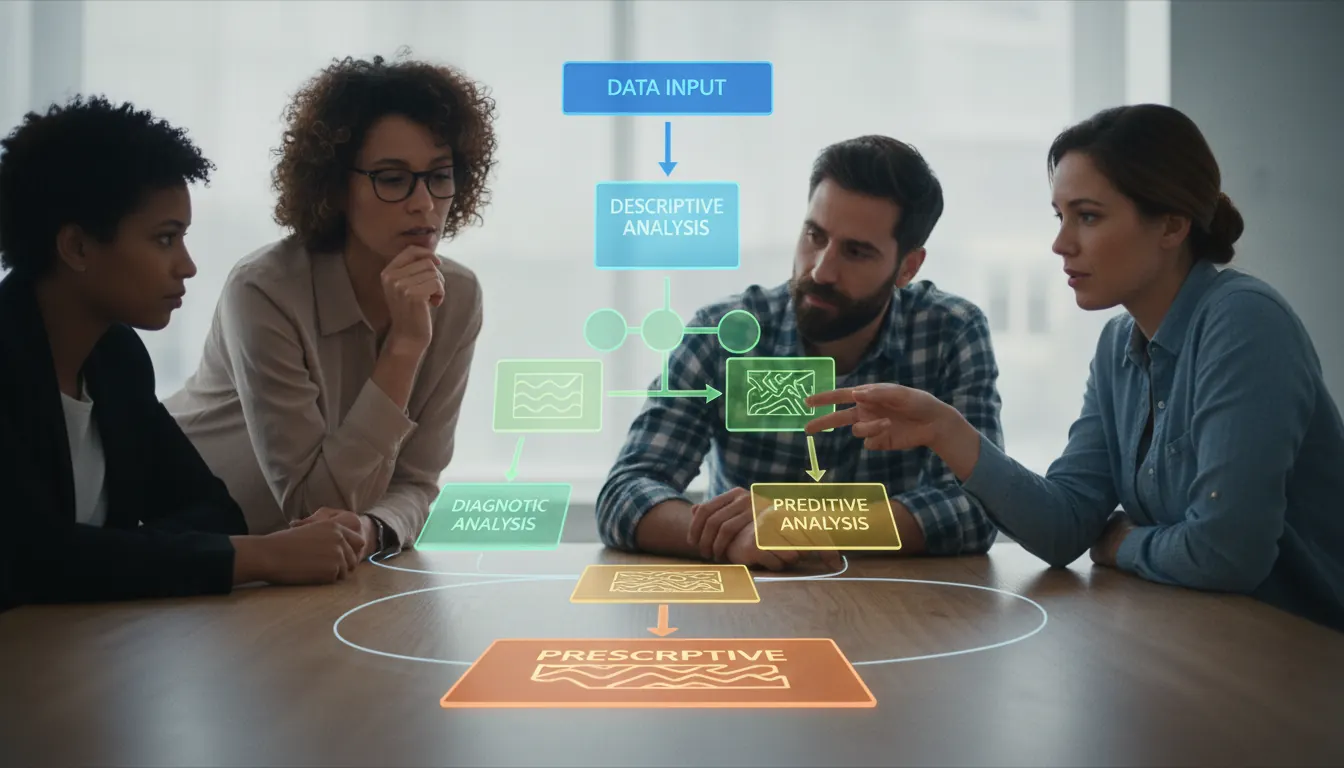
Most practitioners recognize four core types of data analysis. Each answers a different kind of question.
Descriptive analysis summarizes what happened. It produces counts, averages, distributions, and charts. When a researcher reports that 73% of compounds in a dataset showed activity above a threshold, that is descriptive analysis. It does not explain why or predict what comes next — it just describes.
Diagnostic analysis asks why something happened. It digs into the descriptive results to find causes. If a model's accuracy dropped in one dataset partition, diagnostic techniques examine which variables changed and how they correlate with the outcome shift.
Predictive analysis uses historical patterns to forecast future values. Regression models, classification algorithms, and time series forecasting all fall here. In molecular modeling, predictive analysis estimates biological activity for compounds that have not yet been synthesized.
Prescriptive analysis recommends actions. It builds on predictive results to suggest what to do next. This is the least common type in pure research but the most valued in operational settings where decisions must follow from data.
The Data Analysis Process Step by Step
A structured process reduces errors and makes analysis reproducible. The steps are not rigid — real projects loop back when new findings change the questions — but the sequence provides a useful framework.
| Step | Activity | Common Tools |
|---|---|---|
| 1. Define the question | State what you need to know and why | Documentation, team discussion |
| 2. Collect data | Gather relevant datasets from sources | SQL, APIs, lab measurements |
| 3. Clean and prepare | Handle missing values, outliers, formats | Python pandas, R tidyverse |
| 4. Explore | Run initial statistics and visualizations | Jupyter, ggplot2, Matplotlib |
| 5. Model or analyze | Apply chosen methods to the prepared data | Open3DQSAR, scikit-learn, SPSS |
| 6. Interpret and communicate | Draw conclusions, present findings clearly | Reports, dashboards, publications |
"Data cleaning is not glamorous, but analysts who skip it produce results that look precise and are fundamentally wrong."
The cleaning step consistently takes more time than analysts expect. Real datasets contain duplicates, measurement errors, inconsistent units, and missing entries. Fixing these problems before analysis is non-negotiable — bad inputs produce misleading outputs regardless of how sophisticated the subsequent method is.
Key Data Analysis Techniques Explained
Techniques are the specific methods applied during the analysis step. The right choice depends on the data structure, the question, and the assumptions you can reasonably make.
Regression analysis models the relationship between a dependent variable and one or more predictors. Linear regression works when the relationship is roughly proportional. Logistic regression handles binary outcomes. In Open3DQSAR, partial least squares regression connects molecular field descriptors to biological activity measurements.

Clustering groups observations without predefined labels. K-means clustering assigns each data point to the nearest of k cluster centers. Hierarchical clustering builds a tree of nested groups. Both techniques are exploratory — they reveal structure in data without requiring a target variable.
- Regression analysis quantifies relationships between variables and generates predictive equations
- Clustering identifies natural groupings in unlabeled datasets without prior category definitions
- Classification assigns observations to predefined categories using training data as a reference
- Time series analysis models data recorded over regular time intervals to identify trends and seasonality
- Principal component analysis reduces dimensionality while preserving the variance structure of the data
Principal component analysis (PCA) is worth understanding separately. It transforms a dataset with many correlated variables into a smaller set of uncorrelated components. The first component captures the most variance, the second captures the most remaining variance, and so on. In chemometrics, PCA routinely reduces hundreds of molecular descriptors to a handful of components that explain most of the observed activity variation.
Data Analysis vs Data Analytics What Is the Difference
These two terms get used interchangeably, but they describe subtly different things.
Data analysis is the process of examining specific datasets to answer specific questions. It is often retrospective — you have data, you examine it, you draw conclusions. The focus is on the methods and the rigor of the examination.
Data analytics is broader. It describes the whole discipline of extracting value from data, including the tools, infrastructure, business context, and ongoing processes involved. Analytics often implies a continuous operation — dashboards that update in real time, automated pipelines that process new data as it arrives, systems designed for repeated use rather than one-time investigation.
| Aspect | Data Analysis | Data Analytics |
|---|---|---|
| Scope | Specific dataset, specific question | Ongoing discipline and infrastructure |
| Orientation | Often retrospective | Retrospective and real-time |
| Output | Findings and conclusions | Systems, reports, and decisions |
| Role focus | Analyst | Analyst, engineer, business stakeholder |
"Analysis asks what the data shows. Analytics asks how to build systems that continuously turn data into decisions."
In practice, the distinction matters most when scoping a project. A one-time investigation calls for analysis skills. A system that processes thousands of records per day and feeds into operational decisions calls for analytics infrastructure. Confusing the two leads to over-engineering academic projects or under-engineering operational ones.
Choosing the Right Method for Your Data and Question
No single method works for all data types and questions. Choosing well requires understanding both your data structure and what you actually need to know.
Start with the data type. Continuous numerical data supports regression, correlation, and PCA. Categorical data suits chi-square tests and classification models. Time-ordered data needs time series methods. Mixed data types — the most common situation in practice — usually require a preprocessing step that converts everything to a consistent representation before modeling.
Then consider sample size. Some techniques are statistically reliable only with larger datasets. Running a neural network on 40 observations produces an overfit model that generalizes poorly. Simple regression or a t-test may be the honest choice when you have limited data, even if they feel less impressive.
- Match the technique to the data type: continuous, categorical, ordinal, or time-series
- Consider sample size before choosing complex models that require large training sets
- Validate assumptions for each method — regression assumes linearity and normally distributed residuals
- Use cross-validation to test how well a model generalizes to unseen data
- Report uncertainty in results — confidence intervals matter as much as point estimates
Finally, think about interpretability. In regulated environments — clinical trials, regulatory submissions, published research — a method whose output you can explain is worth more than a black-box model with marginally better accuracy. Open3DQSAR's PLS-based approach produces coefficient maps that researchers can inspect and discuss. That transparency supports scientific credibility in ways that more opaque machine learning models often cannot.